Summary
WHAT
Stock Forecast
Daily stock prices of Apple, Amazon, Microsoft, and Tesla over the past 10 years
HOW
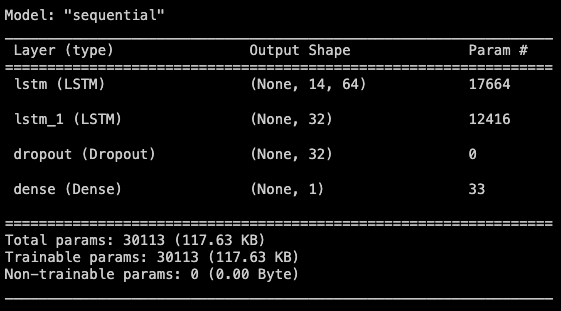
Sequential layers including Dropout, and Dense
RESULTS
5 to 20% error in stock prediction
Microsoft model reach 5% error
Google Colab
Python
Pandas
Scikit-learn
Tensorflow
Keras
Seaborn
Matplotlib
Introduction
Statistics and, more recently, Artificial Intelligence have served as sources of analytical power to address and solve various business problems. Time series analysis, in particular, provides future predictions under different conditions and variable natures. However, some variables are challenging to model, mainly due to the large and diverse number of factors shaping them. Stocks prices fall into this category.
In this study, I explore the application of Recurrent Neural Networks, specifically the Long-Short Term Memory model (LSTM). The model is trained with historical stock prices and explanatory variables to make future predictions for four of the largest technology companies.
Methods
The daily stock prices of Apple, Amazon, Microsoft, and Tesla over the past 10 years (from January 8th, 2014, to January 5th, 2024) were used in this study. The dataset for each date includes the Close (or Last), Volume, Open, High, and Low prices.
The goal of this study was to use 14-day windows to predict the Close variable 1 day ahead. From these windows the Volume, Open, High, and Low prices were used as predictive variables.
As shown in the figure below, the Close variable exhibits irregular growth over the years for each company's stock, with notable noise between 2021 and 2023, especially for Amazon and Tesla.
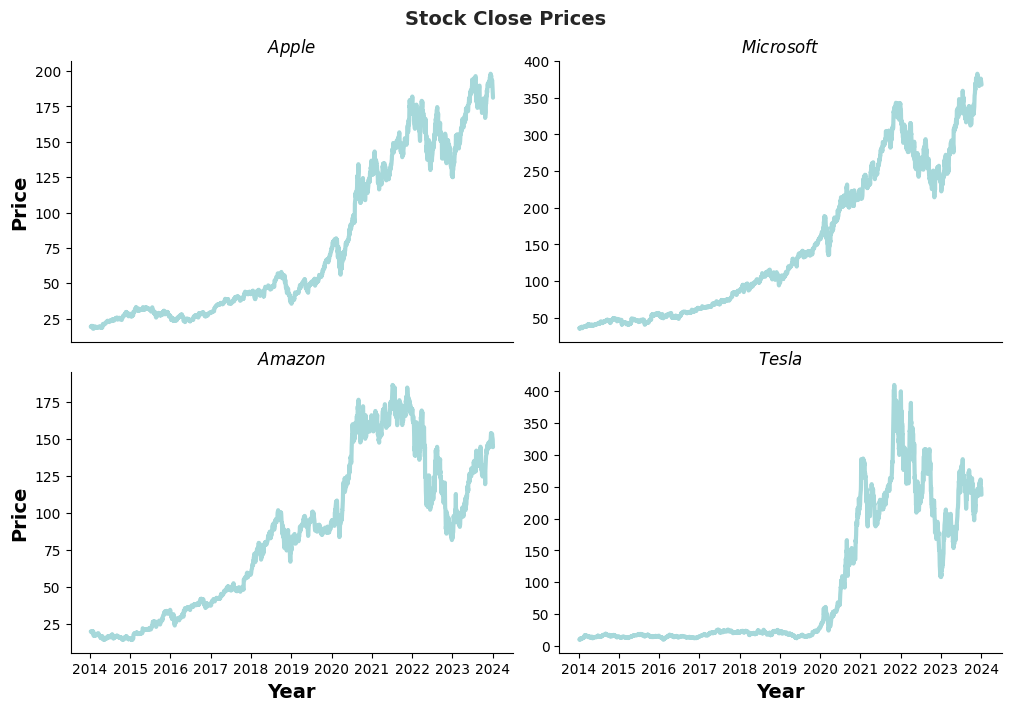
The first 95% of records were used to train the model, of which 10% was allocated as a validation dataset. The validation dataset was employed to validate the model at the end of each epoch, tuning it with new information and checking for potential overfitting. The most recent 126 days (5% of records) were reserved to test the trained model.
All datasets were standardized to bring different variables to a similar scale, ensuring no dominance from their original magnitudes.
The selected model architecture is a sequence of neuron layers, including:
- LSTM: Long-Short Term Memory layer, which takes 14 days window of predictive variables and train to predict 1 day ahead of target variable.
- Dropout: this randomly drops 25% of connections during the training process to prevent overfitting.
- Dense: Fully connected basic neuron layer to process and reduce the output as the final expected result: 4 tumor classification.
ReLU activation function was used for its quick convergence and computational efficiency.
The Adam (Adaptive Moment Estimation) optimizer was employed, dynamically adjusting the learning rate based on individual weights through the incorporation of the first and second moments of the gradient.
In total the model fitted 30,113 parameters in 20 epochs.
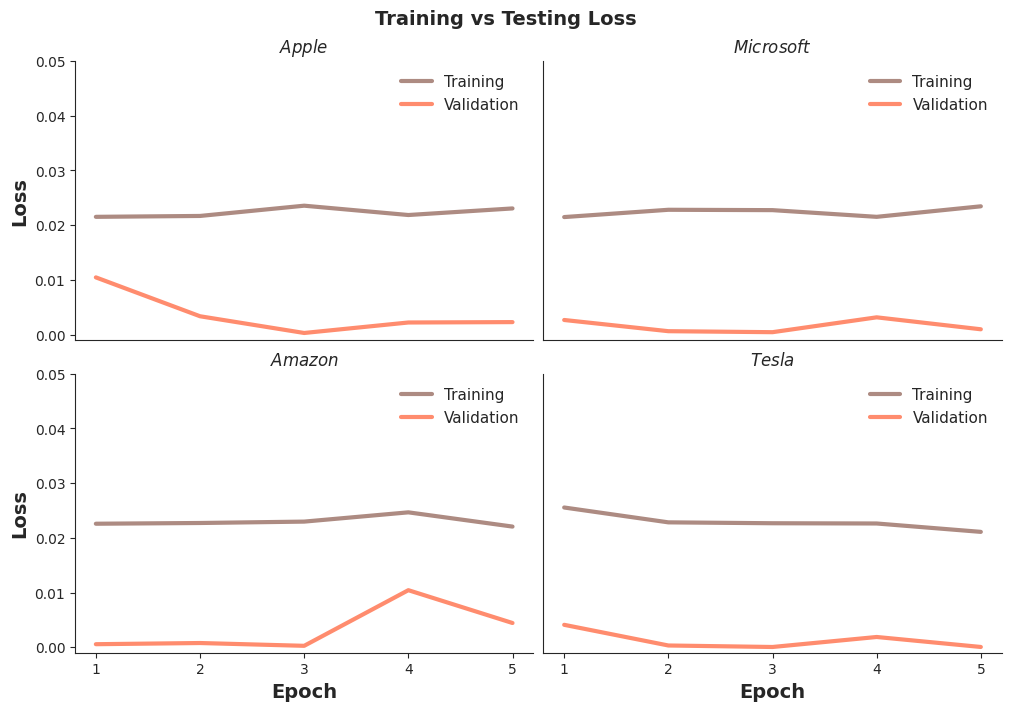
To evaluate the model at each epoch, the Loss function was calculated for training dataset and validation dataset. The Loss function used was Mean Square Error (MSE), which quantifies the error of the model, therefore the lower the better.
With the Loss calculated for each epoch and for training and validation dataset, we can compare them to see sings of overfitting or underfitting.
Finally, the MSE, Root Mean Square Error (RMSE) and Mean Absolute Percentage Error (MAPE) is used to measure the success of the trained model to predict completely new data (testing dataset).
The Python library Pandas were used for data manipulation, Matplotlib and Seaborn for Visualization. The data standardization was made with Scikit-learn Python library. For the Long-Short Term memory models and the rest of the layers, Keras module Layers from Tensorflow was used.
Results
The Loss (MSE) results for Training and Validation datasets show low error for each company's stocks, consistently with lower values for validation predictions. The final Training MSE was less than 0.03, and for Validation MSE, less than 0.02, indicating an immediate good fit at the first epoch with insignificant overfitting.
The testing process demonstrates highly accurate forecasting performance for Microsoft (MAPE < 10%) and very good forecasting performance for Tesla, Apple, and Amazon (MAPE < 20%). This implies that the models could predict the Close price with an average error of 5% in Microsoft, 11% in Tesla, 16% in Apple, and 19% in Amazon.

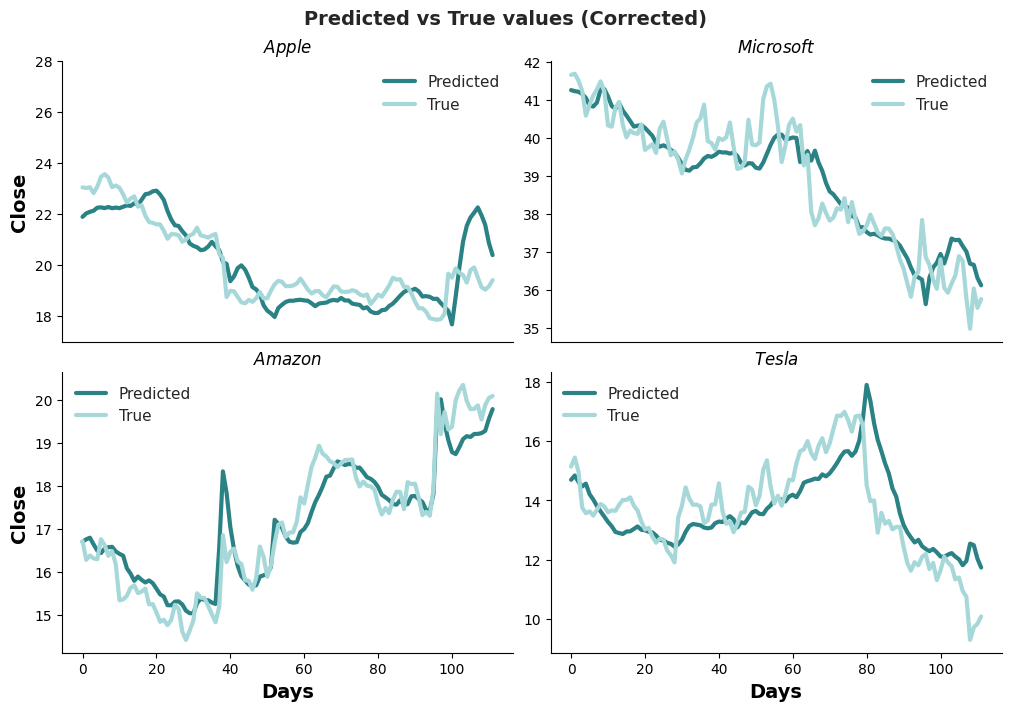
Comparing the Predicted and True values over the 126 days of the testing dataset reveals that the models have a surprisingly accurate representation of the true price tendency. The issue lies more in the magnitude than the movements of the predicted values. The Tesla trained model was less sensitive to this bias than the other models.
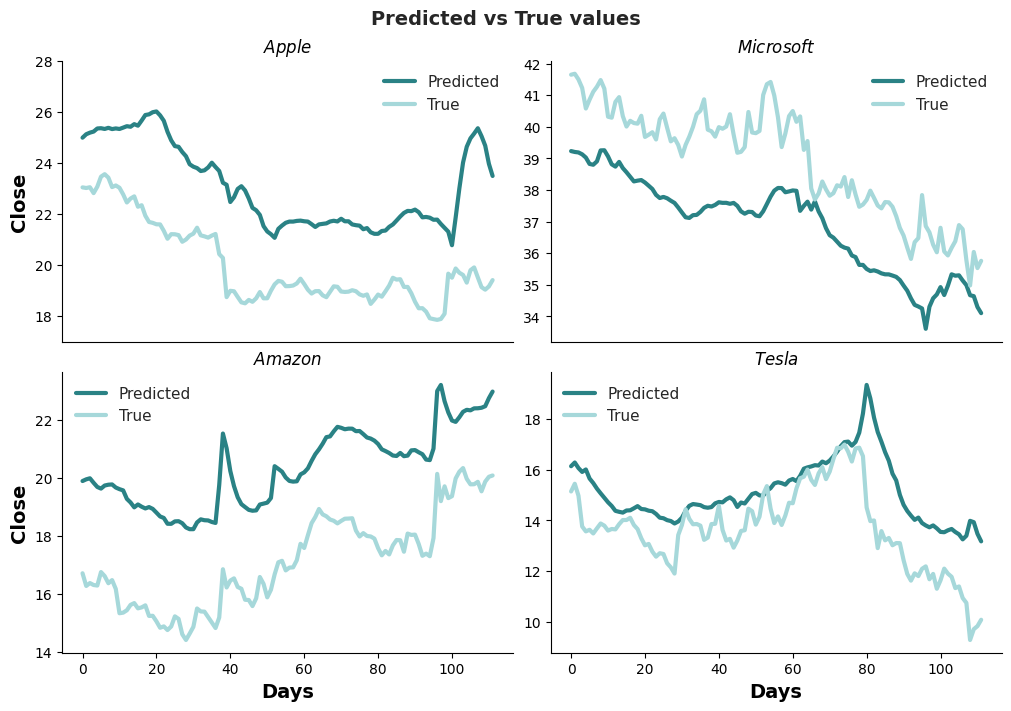
If we correct these magnitude differences by the mean absolute error, the curves for all companies get closer, showing the potential of these models to aid in investment decisions.
Conclusion
The low percentage error in predictions and the use of corrections make Long-Short Term Memory models a valuable source of information in trading activities. Combining these results with other tools and features, such as sentiment analysis of news related to business targets or key announcements from these or other companies, could further enhance prediction power. An AI-driven expert trading consultant for strategic investment decisions, supported by a data-driven system, is now a reality.